Find the Index of the First Occurrence in a String
2024-03-25
- Algorithm
- JavaScript
- LeetCode
문제
알고리즘문제
Given two strings needle and haystack, return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example 1:
Input: haystack = "sadbutsad", needle = "sad" Output: 0
Explanation: "sad" occurs at index 0 and 6. The first occurrence is at index 0, so we return 0.
Example 2:
Input: haystack = "leetcode", needle = "leeto" Output: -1
Explanation: "leeto" did not occur in "leetcode", so we return -1.
Constraints:
1 <= haystack.length, needle.length <= 104
haystack and needle consist of only lowercase English characters.
접근
메서드 중에 indexOf 로 콘솔로 찍어보며 차근히 접근해 보려했는데 맞았다....?
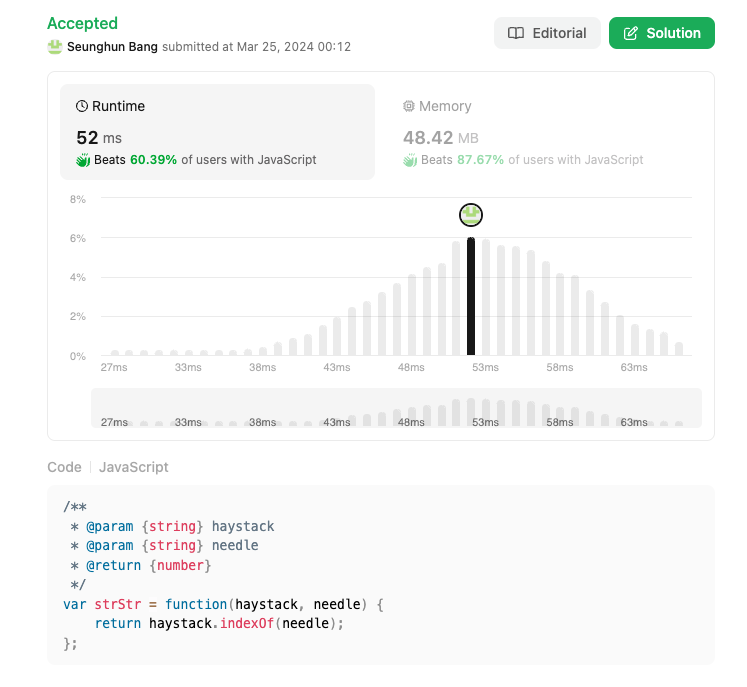
정답 (맞음)
/**
* @param {string} haystack
* @param {string} needle
* @return {number}
*/
var strStr = function(haystack, needle) {
return haystack.indexOf(needle);
};
문제점
효율이 좀 딸리는 듯 하다.
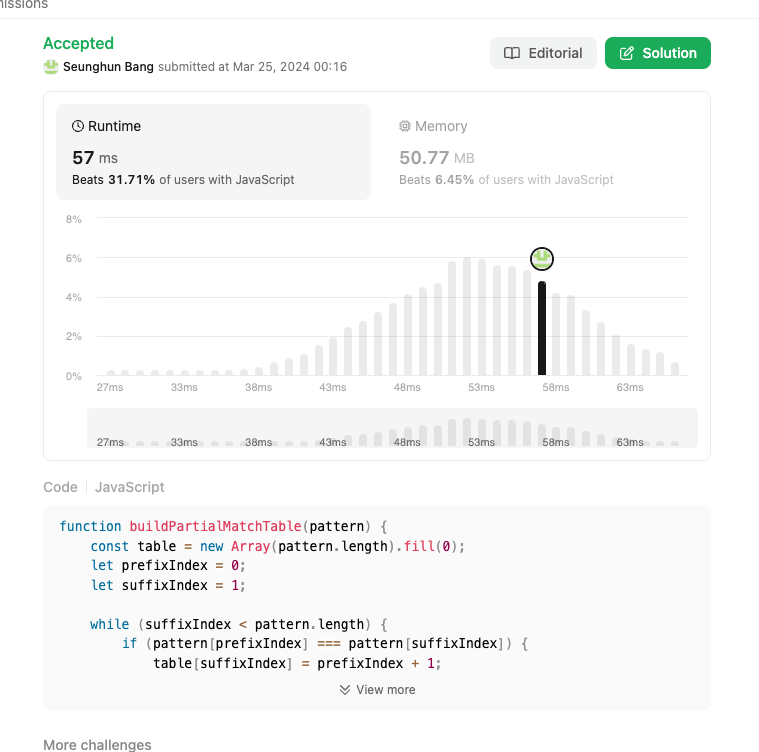
정답 (더 나은 성능)
GPT 센세...
function buildPartialMatchTable(pattern) {
const table = new Array(pattern.length).fill(0);
let prefixIndex = 0;
let suffixIndex = 1;
while (suffixIndex < pattern.length) {
if (pattern[prefixIndex] === pattern[suffixIndex]) {
table[suffixIndex] = prefixIndex + 1;
prefixIndex++;
suffixIndex++;
} else if (prefixIndex === 0) {
table[suffixIndex] = 0;
suffixIndex++;
} else {
prefixIndex = table[prefixIndex - 1];
}
}
return table;
}
function strStr(haystack, needle) {
if (needle.length === 0) return 0;
const lps = buildPartialMatchTable(needle);
let i = 0; // index for haystack
let j = 0; // index for needle
while (i < haystack.length) {
if (haystack[i] === needle[j]) {
i++;
j++;
}
if (j === needle.length) {
return i - j; // Found the pattern
}
if (i < haystack.length && haystack[i] !== needle[j]) {
if (j !== 0) {
j = lps[j - 1];
} else {
i++;
}
}
}
return -1; // Did not find the pattern
}
// Example usage:
const haystack = "sadbutsad";
const needle = "sad";
console.log(kmpSearch(haystack, needle)); // Output: 0
const haystack2 = "leetcode";
const needle2 = "leeto";
console.log(kmpSearch(haystack2, needle2)); // Output: -1
개선된 코드의 설명
여기 KMP (Knuth-Morris-Pratt) 알고리즘을 사용하여 "haystack"에서 "needle"의 첫 번째 발생을 찾는 JavaScript 코드의 예시가 있습니다. KMP 알고리즘은 패턴에서 불일치가 발생했을 때, 이전에 일치했던 문자들에 기반하여 검색 위치를 얼마나 건너뛸지 결정하는 부분 일치 테이블을 사용합니다. 이로 인해 불필요한 비교를 줄이고 효율성을 높일 수 있습니다.
이 코드는 먼저 buildPartialMatchTable 함수를 사용하여 주어진 패턴(needle)에 대한 부분 일치 테이블을 생성합니다. 그 다음, kmpSearch 함수는 이 테이블을 사용하여 주어진 "haystack" 문자열 내에서 "needle" 문자열의 첫 번째 발생 위치를 효율적으로 검색합니다. 만약 "needle"이 "haystack" 내에 존재하지 않는 경우 -1을 반환합니다.
궁금했던 점
일단 속도가 차이가 안난다(오히려 느림)
왜일까??
GPT 센세!
JavaScript에서 .indexOf() 메소드는 매우 최적화되어 있으며, 대부분의 일반적인 사용 사례에서 뛰어난 성능을 제공합니다.
실제로, 내장 함수는 C++나 다른 저수준 언어로 작성되어 엔진 내부에서 실행되므로, 자바스크립트로 작성된 알고리즘과 비교할 때 성능 차이가 크지 않거나 오히려 더 빠를 수 있습니다. 특히, 단순 문자열 검색과 같은 작업에서는 .indexOf() 메소드가 이미 충분히 빠르기 때문에, KMP와 같은 복잡한 알고리즘을 구현하는 것이 실제 성능 이득을 가져다주지 않을 수 있습니다.
그러나, 다음과 같은 상황에서는 KMP 알고리즘과 같은 특수한 문자열 검색 알고리즘이 필요할 수 있습니다:
-
매우 큰 데이터 세트 : 데이터 세트가 매우 크고, 검색 효율성이 중요한 경우, KMP 알고리즘의 최악 시나리오 성능 보장이 중요해질 수 있습니다.
-
특정 패턴의 반복적 검색 : 동일한 패턴을 다양한 문자열에 대해 반복적으로 검색해야 하는 경우, KMP 알고리즘을 사용하면 초기 패턴 분석을 통해 시간을 절약할 수 있습니다.
-
알고리즘 학습 및 이해 : KMP와 같은 알고리즘을 구현하고 이해하는 과정은 알고리즘과 데이터 구조에 대한 깊은 이해를 제공합니다. 이는 프로그래밍 능력을 향상시키고, 더 복잡한 문제를 해결할 수 있는 기반을 마련해 줍니다.
실제 애플리케이션에서는 요구 사항, 데이터의 특성, 성능 목표 등을 종합적으로 고려하여 적절한 도구나 알고리즘을 선택하는 것이 중요합니다. 때로는 내장 함수의 사용이 가장 효율적인 해결책일 수 있으며, 다른 경우에는 알고리즘적 접근이 더 나은 성능을 제공할 수 있습니다.
내 접근법 vs 최적화 접근법 차이
내 접근법
최적화 접근법
차이점 요약
별 차이는 없지만 이미 최적화 되어있는 메서드기 때문에 크게 신경은 안써도 되지만 큰 데이터 세트 / 특정 패턴 반복 검색 에는 필요하다는 것을 배웠다.
오랜만에 리트코드 재밌네!
Java ORM 표...
React Deep...